evpp与asio吞吐量对比
简介
Boost.Asio是用于网络和低层IO编程的跨平台C++库,为开发者提供了C++环境下稳定的异步编程模型。也是业内公认的优秀的C++网络库代表。一般来讲,其他的网络库的性能如果不能与asio做一下全面的对比和评测,就不能令人信服。
本次测试是参考陈硕的博客文章muduo 与 boost asio 吞吐量对比,该文章的结论是:muduo吞吐量平均比asio高 15% 以上。
我们之前做的evpp与[moduo]吞吐量测试性能报告显示,evpp与[moduo]吞吐量基本相当,各自都没有明显的优势。因此我们希望evpp在与boost的性能对比测试中能够占优。
测试对象
- evpp-v0.2.4 based on libevent-2.0.21
- asio-1.10.8
测试环境
- Linux CentOS 6.2, 2.6.32-220.7.1.el6.x86_64
- Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
- gcc version 4.8.2 20140120 (Red Hat 4.8.2-15) (GCC)
测试方法
依据 boost.asio 性能测试 http://think-async.com/Asio/LinuxPerformanceImprovements 的办法,用 ping pong 协议来测试吞吐量。
简单地说,ping pong 协议是客户端和服务器都实现 echo 协议。当 TCP 连接建立时,客户端向服务器发送一些数据,服务器会 echo 回这些数据,然后客户端再 echo 回服务器。这些数据就会像乒乓球一样在客户端和服务器之间来回传送,直到有一方断开连接为止。这是用来测试吞吐量的常用办法。
evpp的测试代码在软件包内的路径为benchmark/throughput/evpp,代码如https://github.com/Qihoo360/evpp/tree/master/benchmark/throughput/evpp所示。并使用 tools目录下的benchmark-build.sh
asio的测试代码直接使用陈硕recipes的实现,具体代码在这里https://github.com/chenshuo/recipes/tree/master/pingpong/asio。
我们做了下面两项测试:
- 单线程测试,测试并发连接数为 1/10/100/1000/10000 时,消息大小分别为 4096 8192 81920 409600 时的吞吐量
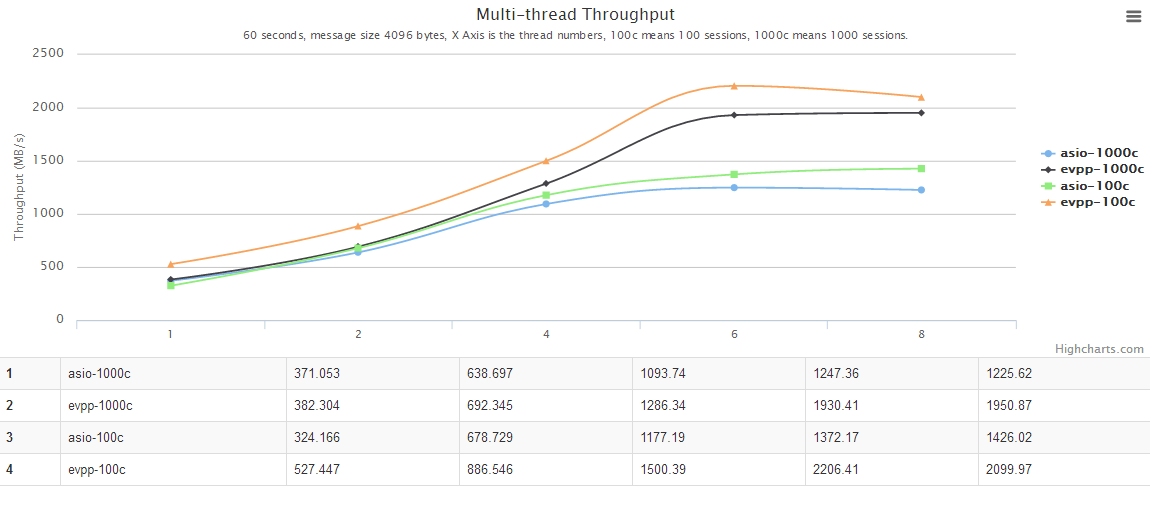
- 多线程测试,并发连接数为 100 或 1000,服务器和客户端的线程数同时设为 2/3/4/6/8,ping pong 消息的大小为 4096 bytes。测试用的 shell 脚本可从evpp的源码包中找到。
测试结果数据
最终测试结论如下:
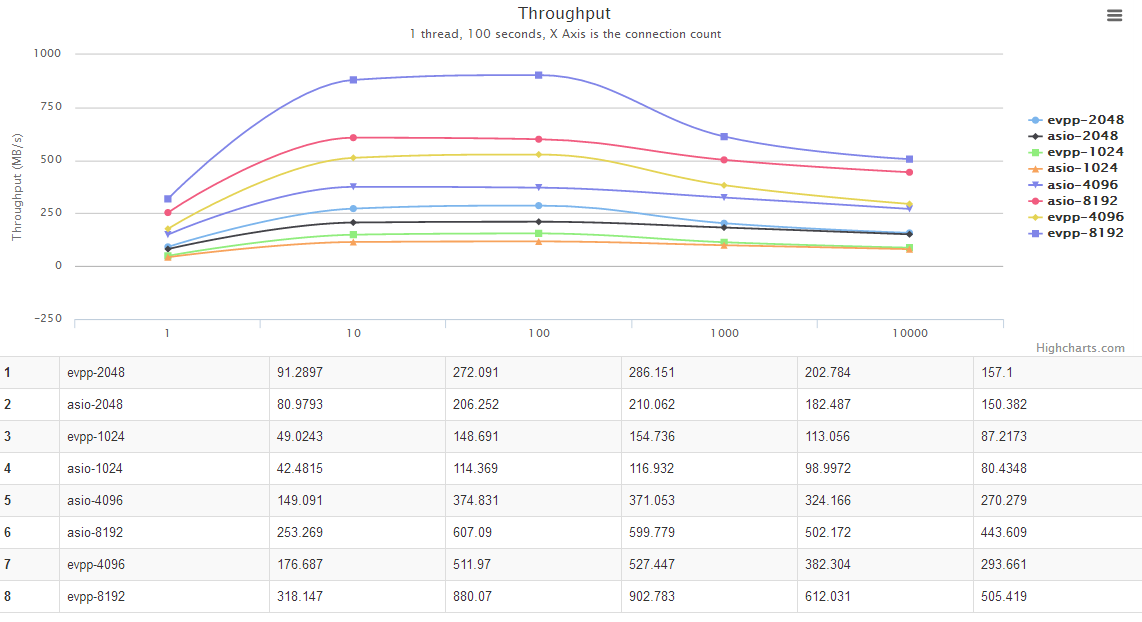
在吞吐量方面的性能总体来说,evpp比asio整体上明显更快,吞吐量高出大约20%~50%
单线程测试数据
横轴是并发数。纵轴是吞吐量,越大越好。
图表中的evpp-1024表示消息大小为1024字节,其他以此类推,例如evpp-4096表示消息大小为4096字节。
多线程测试数据
横轴是线程个数。纵轴是吞吐量,越大越好。
分析
我们有些怀疑上述的测试数据中asio的性能太过差,这当不起boost的大名。另外陈硕的博客muduo 与 boost asio 吞吐量对比中也提到一些想法:猜测其主要原因是测试代码只使用了一个 io_service,如果改用“io_service per CPU”的话,性能应该有所提高。于是我们找到公司内对asio非常熟悉的大牛胡大师操刀写了一个全新的测试程序,具体代码请见 https://github.com/huyuguang/asio_benchmark。 版本号:commits 21fc1357d59644400e72a164627c1be5327fbe3d,并用client2/server2测试用例。 测试的脚本用 single_thread.sh 和 multiple_thread.sh。
新的一轮测试下来,我们发现asio的性能上来的,与evpp [moduo]等库相当。
测试结论
单线程场景
详情请见下面图表,横轴是并发数。纵轴是吞吐量,越大越好。
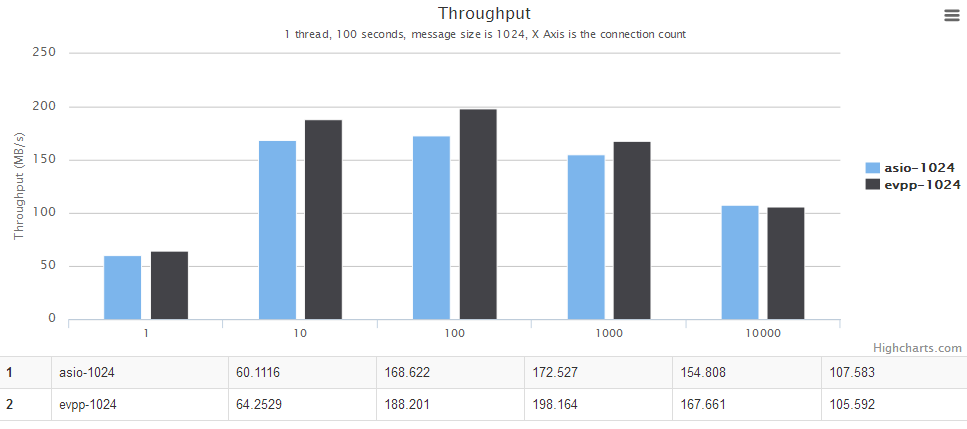
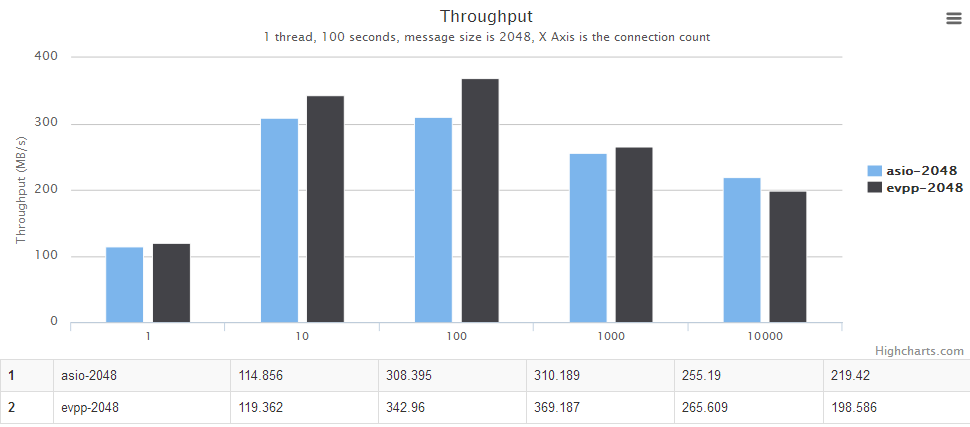
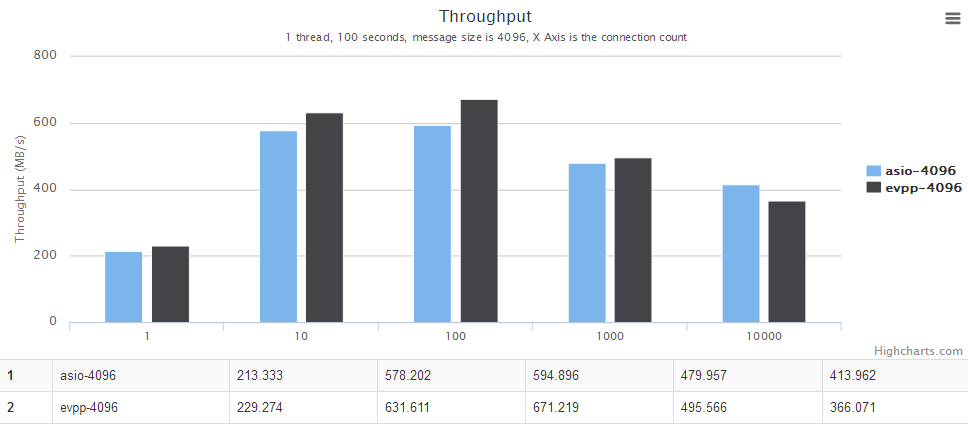
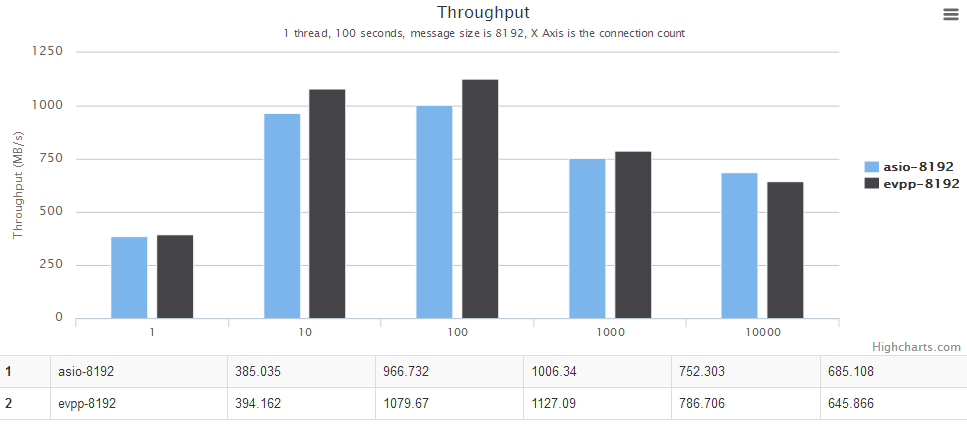
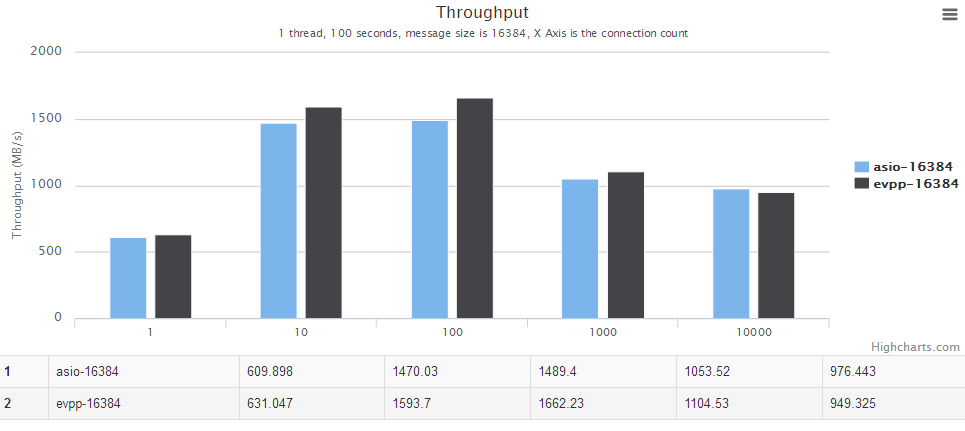
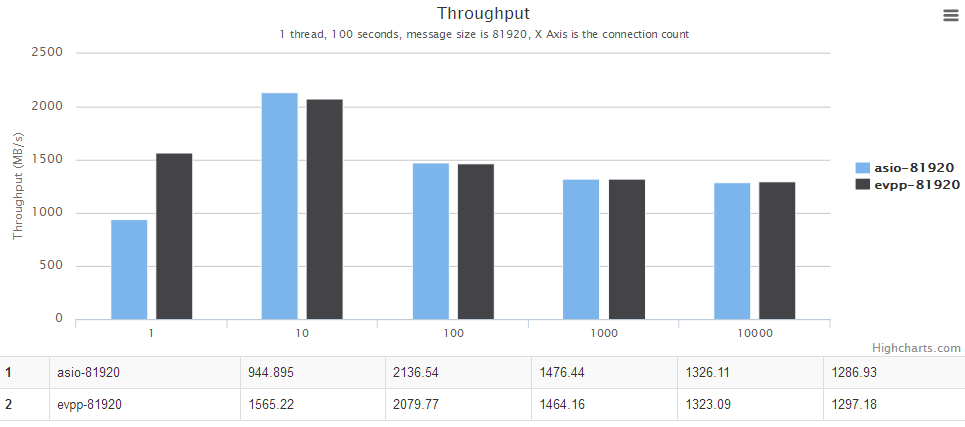
多线程场景
详情请见下面图表,横轴是线程个数。纵轴是吞吐量,越大越好。
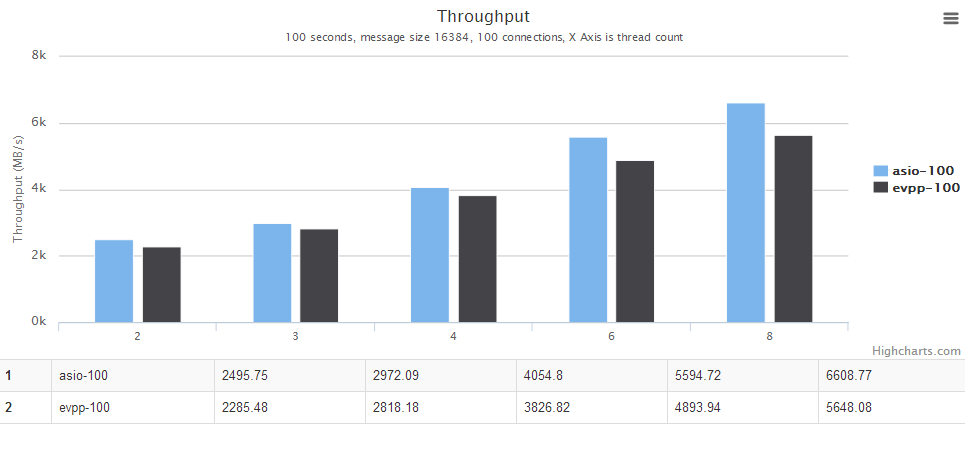
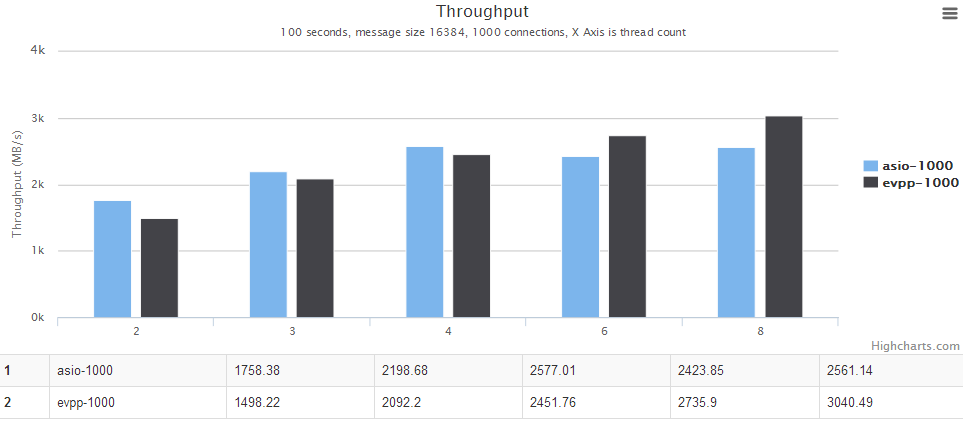
进一步分析
在陈硕的测试中,asio的那个程序没有发挥出应有的性能,绝对与测试程序本身有关,而不是说asio性能差,这从第二次测试结果可以看出来。
在第二次测试中的多线程并发数为100的场景下,asio性能比evpp高出 10% 左右,一开始以为是evpp本身的性能在该场景下差一点,但后来仔细分析了胡大师写的这个测试代码 https://github.com/huyuguang/asio_benchmark 发现,这种ping pong测试中,正好能利用asio的Proactor的优势,他几乎没有内存分配,每次只读固定大小的数据然后发送出去,然后用通用的BUFFER来进行下一次读取操作。而evpp是Reactor模式的网络库,其读取数据很可能不是固定的大小,这就涉及到了一些evpp::Buffer内部的内存重分配问题,导致过多的内存分配、释放、拷贝等动作。
因此,我们准备再做一轮测试,具体方法是模拟现实应用场景下消息长度不可能固定不变的,每个消息包括两部分,前面是HEADER,后面是BODY,HEADER中有BODY的长度,然后让BODY长度从1增长到100k大小,最后看看两者之间的性能对比数据。
All benchmark reports
The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue : boost::lockfree::queue is better, the average is higher than queue with std::mutex about 75%~150%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
最后
报告中的图表是使用gochart绘制的。
非常感谢您的阅读。如果您有任何疑问,请随时在issue跟我们讨论。谢谢。